Run Multimodal Reasoning Agents with NVIDIA Nemotron on vLLM
We are excited to release NVIDIA Nemotron Nano 2 VL, supported by vLLM. This open vision language model (VLM) is built for video understanding and document intelligence.
Nemotron Nano 2 VL uses a hybrid Transformer–Mamba design and delivers higher throughput while maintaining state-of-the-art multimodal reasoning accuracy. The model also features Efficient Video Sampling (EVS), a new technique that reduces redundant tokens generation for video workloads , allowing processing of more videos with higher efficiency.
In this blog post, we’ll explore how Nemotron Nano 2 VL advances video understanding and document intelligence, showcase real-world use cases and benchmark results, and guide you through getting started with vLLM for inference to unlock high-efficiency multimodal AI at scale.
Leading multimodal model for efficient video understanding and document intelligence
NVIDIA Nemotron Nano 2 VL brings both video understanding and document intelligence capabilities together in a single, highly efficient model. Built on the hybrid Transformer–Mamba architecture, it combines the reasoning strength of Transformer models with the compute efficiency of Mamba, achieving high throughput and low latency, allowing it to process multi-image inputs faster.
Trained on NVIDIA-curated, high-quality multimodal data, Nemotron Nano 2 VL leads in video understanding and document intelligence benchmarks such as MMMU, MathVista, AI2D, OCRBench, OCRBench-v2, OCR-Reasoning, ChartQA, DocVQA, and Video-MME, delivering top-tier accuracy in multimodal reasoning, character recognition, chart reasoning, and visual question answering. This makes it ideal for building multimodal applications that automate data extraction and comprehension across videos, documents, forms, and charts with enterprise-grade precision.
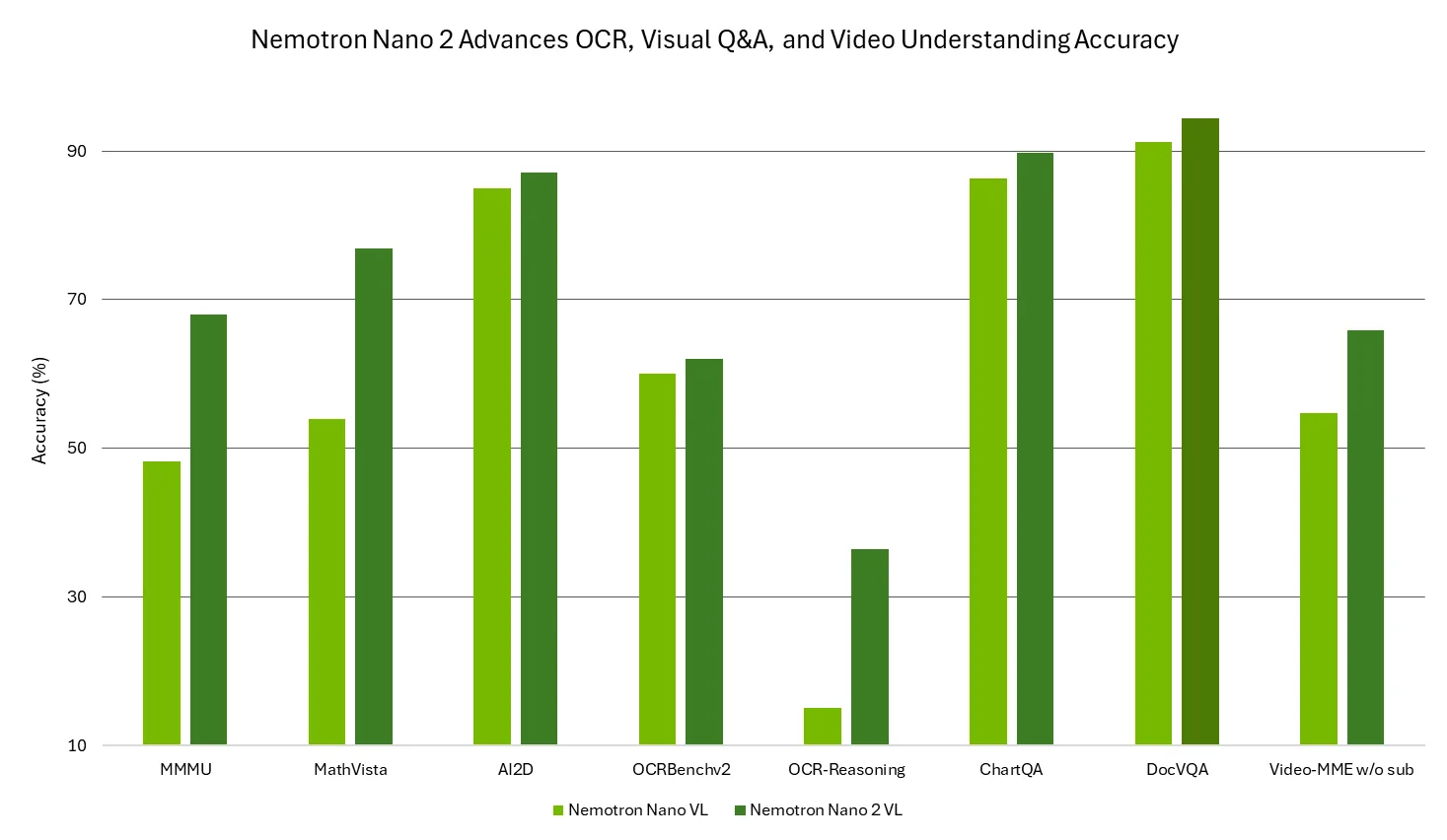
Figure 1: Nemotron Nano 2 VL provides leading accuracy on various video understanding and document intelligence benchmarks
Improving Efficiency with EVS
With EVS, the model achieves higher throughput and faster response times without sacrificing accuracy. EVS technique prunes redundant frames, preserving semantic richness while enabling longer video processing efficiently. As a result, enterprises can analyze hours of footage, from meetings and training sessions to customer calls, in minutes, gaining actionable insights faster and at lower cost.
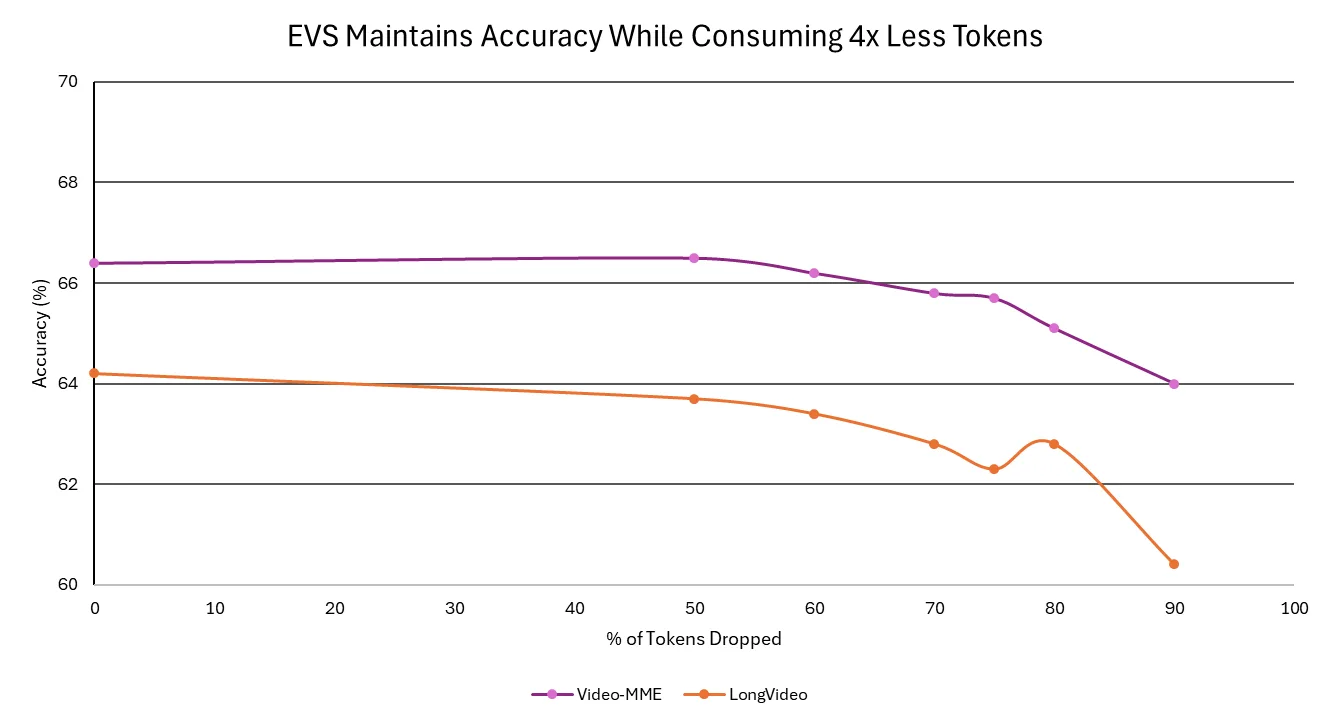
Figure 2: Accuracy trend of the Nemotron Nano 2 VL model across various token-drop thresholds using efficient video sampling on Video-MME and LongVideo benchmarks
About Nemotron Nano 2 VL
- Architecture:
- CRADIOH-V2 based Vision Encoder
- Efficient video sampling as token compression module
- Hybrid Transformer-Mamba Architecture- Nemotron Nano 2 LLM backbone with reasoning.
- Accuracy
- Leading accuracy on OCRBench v2
- 74 on average score (compared to 64.2 with current top VL model) on the following benchmarks: MMMU, MathVista, AI2D, OCRBench, OCRBench-v2, OCR-Reasoning, ChartQA, DocVQA, and Video-MME
- Model size: 12B
- Context length: 128k
- Model input: Multi-image documents, videos, text
- Model output: Text
- Get started:
- Download model weights from Hugging Face - BF16, FP8, FP4-QAD
- Run with vLLM for inference
- Technical report to build custom, optimized models with Nemotron techniques..
Run optimized inference with vLLM
This guide demonstrates how to run Nemotron Nano 2 VL on vLLM, achieving accelerated inference and serving concurrent requests efficiently with BF16, FP8 and FP4 precision support.
Install vLLM
The support for Nemotron Nano 2 VL is available in the nightly version of vLLM. Run the command below to install vLLM:
uv venv
uv pip install vllm --extra-index-url https://wheels.vllm.ai/nightly --prerelease=allow
Deploy and query the inference server
Deploy an OpenAI-compatible inference server with vLLM by running the following commands for BF16, FP8 and FP4 precision:
vllm serve nvidia/Nemotron-Nano-12B-v2-VL-BF16 --trust-remote-code --dtype bfloat16 --video-pruning-rate 0
# FP8
vllm serve nvidia/Nemotron-Nano-VL-12B-V2-FP8 --trust-remote-code --quantization modelopt --video-pruning-rate 0
# FP4
vllm serve nvidia/Nemotron-Nano-VL-12B-V2-FP4-QAD --trust-remote-code --quantization modelopt_fp4 --video-pruning-rate 0
Once the server is up and running, you can prompt the model using the below code snippet:
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="null")
# Simple chat completion
resp = client.chat.completions.create(
model="nvidia/Nemotron-Nano-12B-v2-VL-BF16",
messages=[
{"role": "system", "content": "/no_think"},
{"role": "user", "content": [
{"type": "text", "text": "Give me 3 interesting facts about this image."},
{"type": "image_url", "image_url": {"url": "https://blogs.nvidia.com/wp-content/uploads/2025/08/gamescom-g-assist-nv-blog-1280x680-1.jpg"}
}
]},
],
temperature=0.0,
max_tokens=1024,
)
print(resp.choices[0].message.content)
For more examples, check out our vLLM cookbook: Nemotron-Nano2-VL/vllm_cookbook.ipynb
Share your ideas and vote on what matters to help shape the future of Nemotron.
Stay up to date on NVIDIA Nemotron by subscribing to NVIDIA news and following NVIDIA AI on LinkedIn, X, YouTube, and the Nemotron channel on Discord.